[§]
introvertlogic
/ LAB LEDGER
Home
AI
About
Playbook
INTROVERTLOGIC · LAB LEDGER
ARCHIVE FILTER
APR 2026
§ FILTER · กรองตามหมวด
Category:
AI
Posts in AI pillar
§ ENTRIES IN THIS FILTER
AI
คนสร้าง Fable 5 ยังบอกว่าตัวเองเป็นมือใหม่ — ผมฟังแล้วโล่งใจ
12 Jun 2026
AI
ทักษะที่ AI แทนไม่ได้ บทเรียนจากงานเงินล้านในวงการ AI
8 Jun 2026
AI
ติดตั้งคำสั่งเดียว ได้ AI ที่อ่าน Reddit ทั้งโลกให้
7 Jun 2026
AI
ความจำ ChatGPT แบบใหม่ — มันจำคุณเองแล้ว ดีหรือน่ากลัว
7 Jun 2026
AI
รัน AI บนเครื่องตัวเอง — คนสร้าง Redis ทำให้ฟรีแค่ไหน
7 Jun 2026
AI
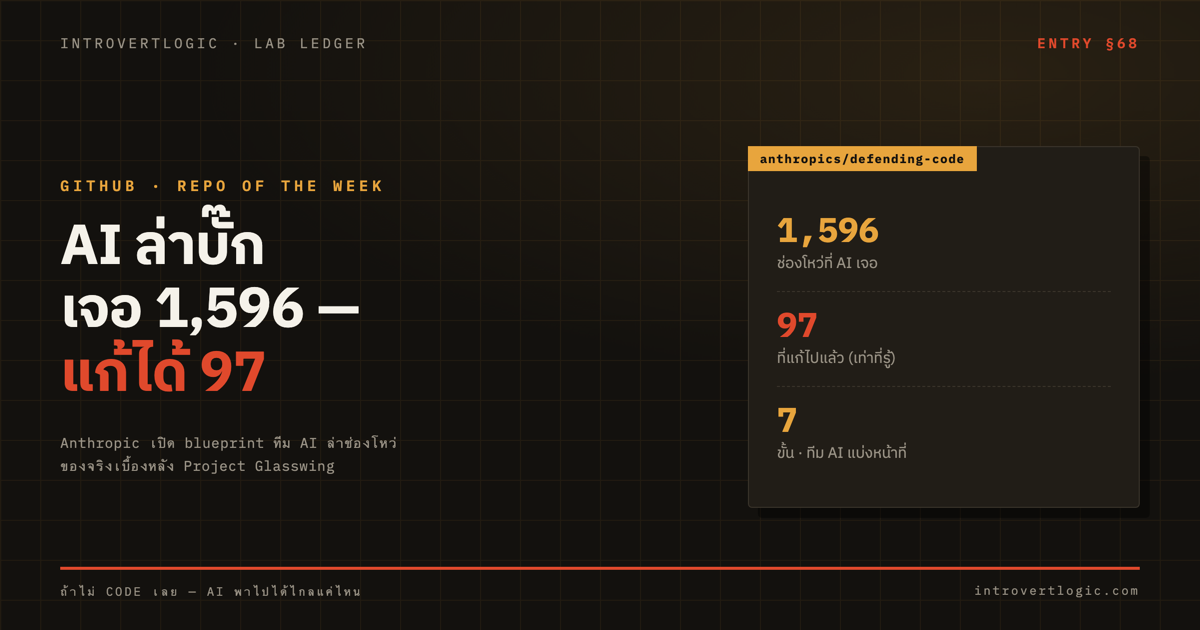
Anthropic เปิด AI ล่าบั๊ก — เจอ 1,596 ช่องโหว่ แก้ได้ 97
6 Jun 2026
AI
บิล Claude เปลี่ยน 15 มิ.ย. — ใครกระทบ ใครไม่ต้องตกใจ
6 Jun 2026
AI
caveman: สั่ง AI พูดสั้นแบบมนุษย์ถ้ำ เพื่อลด token 2 ใน 3
6 Jun 2026
AI
ตามข่าว AI ไม่ทัน? จริงๆ แล้วไม่ต้องตามทุกตัว
6 Jun 2026
AI
AI หาช่องโหว่เก่งกว่ามนุษย์แล้ว — แล้วเว็บที่ผมไม่ได้เขียนเองล่ะ?
5 Jun 2026
Previous Page
1
2
3
4
…
8
Next Page
← BACK TO LEDGER