ตอนนี้มีโมเดล AI ที่เก่งที่สุดในโลกอยู่จริง ทำคะแนนนำเกือบทุกแบบทดสอบความสามารถเท่าที่มีตอนนี้
แต่เราใช้ตัวนั้นไม่ได้ — ได้แค่ “เวอร์ชันที่ปลอดภัย” ของมัน
9 มิถุนายน Anthropic ปล่อยของออกมา คู่หนึ่ง: Fable 5 กับ Mythos 5 เป็นโมเดลตัวเดียวกันเป๊ะ ต่างกันแค่ “ใครได้ใช้แบบไหน” — Fable 5 คือเวอร์ชันที่เปิดให้คนทั่วไป มีระบบนิรภัยคุมอยู่ ส่วน Mythos 5 คือตัวเต็มที่ถอดเบรกบางอย่างออก เปิดให้เฉพาะผู้เชี่ยวชาญความปลอดภัยไซเบอร์และพาร์ตเนอร์ที่ได้รับเลือก (ผ่านโครงการ Glasswing ร่วมกับรัฐบาลสหรัฐฯ)
ถ้าถาม Fable 5 เรื่องไซเบอร์ ชีวเคมี หรือการกลั่นโมเดล มันจะ “เด้ง” ให้ Claude Opus 4.8 (รุ่นก่อน) ตอบแทนอัตโนมัติ — เกิดราวไม่ถึง 5% ของการใช้งาน คนบน Reddit ตั้งข้อสังเกตว่านี่คือจุดเริ่มของโลก AI สองชั้น: ตัวเต็มให้คนวงใน ตัว “เซฟ” ให้ที่เหลือ
(จริง ๆ ผมเคยเขียนเรื่อง Mythos ไว้ตั้งแต่ตอนมันโผล่มาเป็น preview — Claude Mythos: AI ที่ Anthropic ไม่ยอมปล่อยให้คุณใช้ — ตอนนั้นยังเป็นของลับเฉพาะคนวงใน ตอนนี้มันออกมาให้คนทั่วไปในชื่อ Fable 5 แล้ว)
เถียงกันได้ทั้งวันว่าควรไม่ควร — แต่มีอีกเรื่องที่ practical กว่าและคนมองข้าม
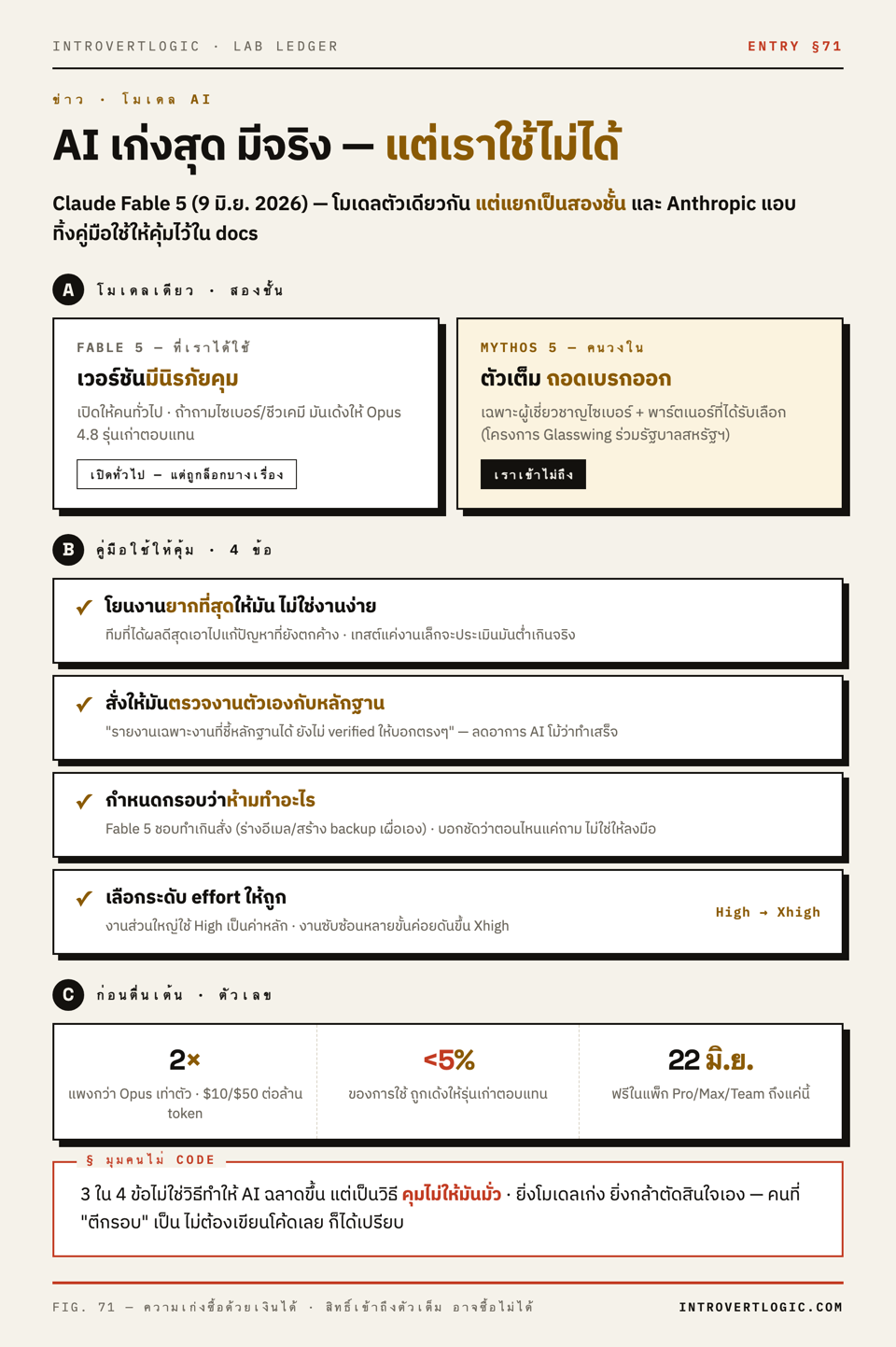
Anthropic แอบทิ้งคู่มือใช้ Fable 5 ไว้ใน docs
ของที่เรา ได้ ใช้ (Fable 5) ก็ยังเป็นตัวแรงสุดที่เคยเปิดให้คนทั่วไปอยู่ดี และ Anthropic เขียน คู่มือ prompt มันโดยเฉพาะ ฝังไว้ในหน้า API docs ที่คนส่วนใหญ่ไม่เข้าไปอ่าน นี่คือ 4 ข้อที่หยิบไปใช้ได้เลย:
1. โยนงานที่ “ยากที่สุด” ให้มัน ไม่ใช่งานง่าย Anthropic บอกตรงๆ ว่าทีมที่ได้ผลดีที่สุดคือทีมที่เอา Fable 5 ไปจัดการปัญหาที่ยังแก้ไม่ตก งานที่กินเวลาเป็นชั่วโมง เป็นวัน เป็นสัปดาห์ ถ้าเอาไปทดสอบแค่งานเล็กๆ จะ “ประเมินมันต่ำเกินจริง”
2. สั่งให้มัน “ตรวจงานตัวเองกับหลักฐานจริง” บอกมันว่า “รายงานเฉพาะงานที่ชี้หลักฐานได้ ถ้ายังไม่ verified ให้บอกตรงๆ ว่ายัง” Anthropic เคลมว่าวิธีนี้ลดอาการ AI “โม้ว่าทำเสร็จแล้ว” ได้ชัดเจน แม้แต่ในงานที่จงใจหลอกให้มันโม้
3. กำหนดกรอบว่า “ห้ามทำอะไร” Fable 5 ชอบทำเกินสั่ง — ร่างอีเมลที่ไม่ได้ขอ สร้าง backup git เผื่อเอง คู่มือแนะนำให้บอกชัดว่าเมื่อไหร่ “ห้ามลงมือ” เช่น เวลาเราแค่ถามหรือคิดดังๆ ไม่ได้สั่งให้แก้ — สิ่งที่ต้องการคือ “ความเห็น” ไม่ใช่ให้มันไปรื้องานเลย
4. เลือกระดับ effort ให้ถูก ใช้ High เป็นค่าหลักกับงานส่วนใหญ่ · งานซับซ้อนหลายขั้นค่อยดัน Xhigh
มุมคนไม่ code: ยิ่งแรง ยิ่งต้อง “กำกับ” เป็น
สังเกตไหมว่า 3 ใน 4 ข้อนี้ ไม่ใช่วิธีทำให้ AI ฉลาดขึ้น — แต่เป็นวิธี คุมไม่ให้มันมั่ว ทั้งสั่งตรวจงานตัวเอง ทั้งห้ามทำเกินสั่ง
นี่คือบทเรียนที่เซอร์ไพรส์: โมเดลยิ่งเก่ง มันยิ่งกล้าตัดสินใจเอง และยิ่งต้องการคนที่ “ตีกรอบ” เป็น — ทักษะนี้ไม่ต้องเขียนโค้ดเลย แค่สื่อสารให้ชัดว่าอยากได้อะไร และ ไม่ อยากได้อะไร ในแง่นี้ คนไม่ code ที่สั่งงานเป็น อาจได้เปรียบกว่าที่คิด — และมันก็ตรงข้ามกับอีกทางที่เราเพิ่งเล่าไป คือ การรัน AI เองบนเครื่องตัวเอง ที่ไม่ต้องพึ่งสิทธิ์เข้าถึงของใคร สองทางนี้กำลังวิ่งสวนกัน
กับดักก่อนตื่นเต้น
- แพง 2 เท่า — Fable 5 อยู่ที่ $10 / $50 ต่อล้าน token (เข้า/ออก) เทียบกับ Opus 4.8 มาตรฐานที่ $5 / $25 คือเท่าตัวพอดี
- ฟรีมีหมดอายุ — ตอนนี้รวมในแพ็ก Pro/Max/Team ฟรีถึง 22 มิ.ย. หลังจากนั้น (23 มิ.ย.) ถูกถอดออกไปคิดตามการใช้ ใครจะลองรีบ
- เบื้องหลังคือสงครามราคา — บน X มีบทสนทนาว่าทั้ง OpenAI และ Anthropic กำลังจะหั่นราคาแย่งลูกค้ากัน ทั้งคู่ยังขาดทุนหลายพันล้าน “ของแพงวันนี้” จึงอาจถูกลงเร็วกว่าที่คิด — รอได้ก็รอ
คำถามที่ค้างในหัวผมหลังอ่านจบ ไม่ใช่ “Fable 5 เก่งแค่ไหน” แต่เป็น “ใครได้ใช้ตัวเต็ม แล้วเราอยู่ชั้นไหน” — ความเก่งของ AI ไล่ตามทันได้ด้วยเงิน แต่ “สิทธิ์เข้าถึงตัวที่ไม่ถูกล็อก” อาจเป็นเส้นแบ่งใหม่ที่เงินอย่างเดียวซื้อไม่ได้
ข้อมูลจากประกาศและคู่มือทางการของ Anthropic (9–10 มิ.ย. 2026) ผมยังไม่ได้ลอง Fable 5 เองเพราะราคาและ access — นี่คือสิ่งที่ Anthropic บอกเอง ไม่ใช่รีวิวจากการใช้จริง · ส่วนตัว: ข้อ 2 กับ 3 เอาไปใช้กับ AI ตัวไหนก็ได้ ไม่ต้องรอ Fable 5